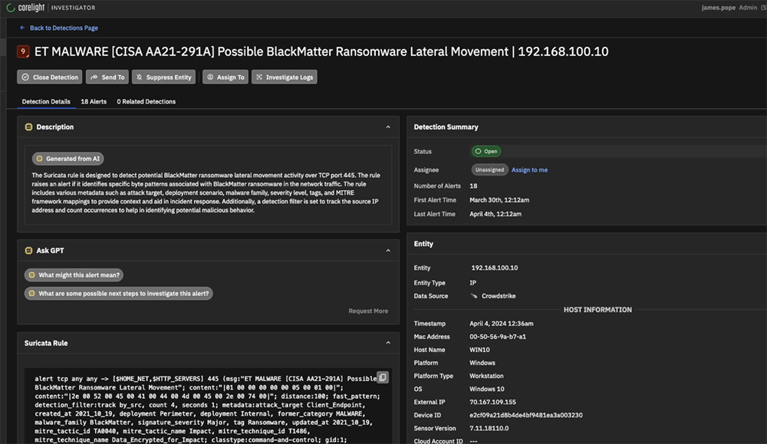
Close your ransomware case with Open NDR

Corelight now powers CrowdStrike solutions and services


Alerts, meet evidence.


5 Ways Corelight Data Helps Investigators Win

10 Considerations for Implementing an XDR Strategy

Don't trust. Verify with evidence


NDR for Dummies

The Power of Open-Source Tools for Network Detection and Response


The Evolving Role of NDR

Detecting 5 Current APTs without heavy lifting

Network Detection and Response

Featured Post
April
30,
2024
The big idea behind Corelight has always been simple: ground truth is priceless. What really happened, both now and looking back in time. Whether it is used to detect attacks, investigate routine alerts, respond to new vulnerabilities or a full scale incident response, the constant is that ground truth makes everything in security better. Read more »