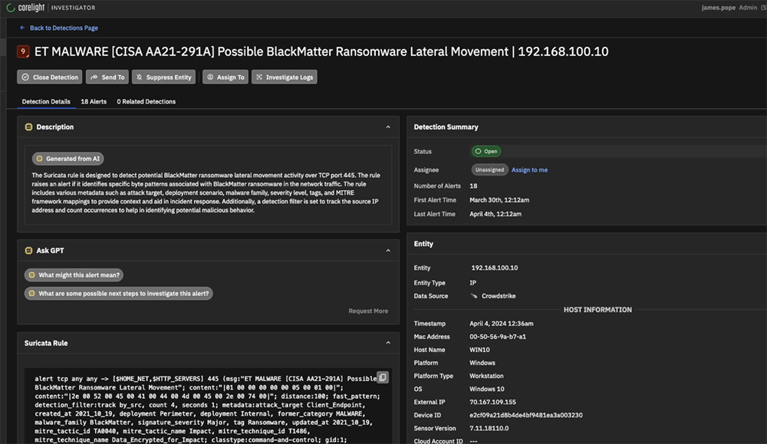
Close your ransomware case with Open NDR

Corelight now powers CrowdStrike solutions and services


Alerts, meet evidence.


5 Ways Corelight Data Helps Investigators Win

10 Considerations for Implementing an XDR Strategy

Don't trust. Verify with evidence


NDR for Dummies

The Power of Open-Source Tools for Network Detection and Response


The Evolving Role of NDR

Detecting 5 Current APTs without heavy lifting

Network Detection and Response

Featured Post
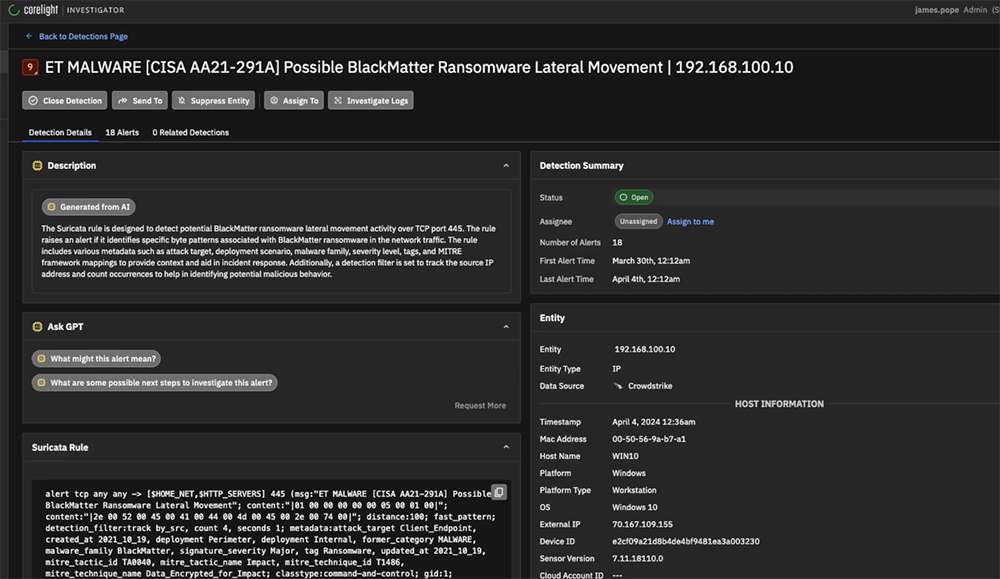 April
24,
2024
April
24,
2024
In the ever-evolving landscape of cybersecurity threats, staying ahead requires more than just detection; it demands comprehensive correlation and analysis for informed decision-making. Understanding the context surrounding an alert is important to effectively mitigate risk. That's why we're thrilled to announce the integration of CrowdStrike... Read more »